Paper: https://arxiv.org/pdf/2401.03191.pdf
In the rapidly evolving landscape of computer vision, the pursuit of accurate per-object distance estimation stands as a cornerstone for safety-critical applications, ranging from autonomous driving to surveillance and robotics. The nuances of long-range object detection, occlusion challenges, and complex visual patterns have spurred the development of innovative approaches that enhance local and global cues. In this context, our latest research introduces DistFormer – a novel architecture designed to revolutionize per-object distance estimation by synergizing robust context encoding, self-supervised learning, and global refinement of the targets in the scene.
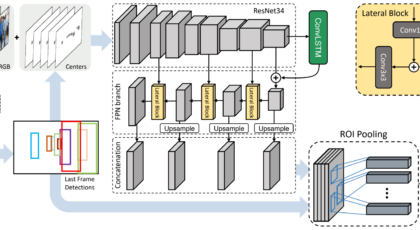
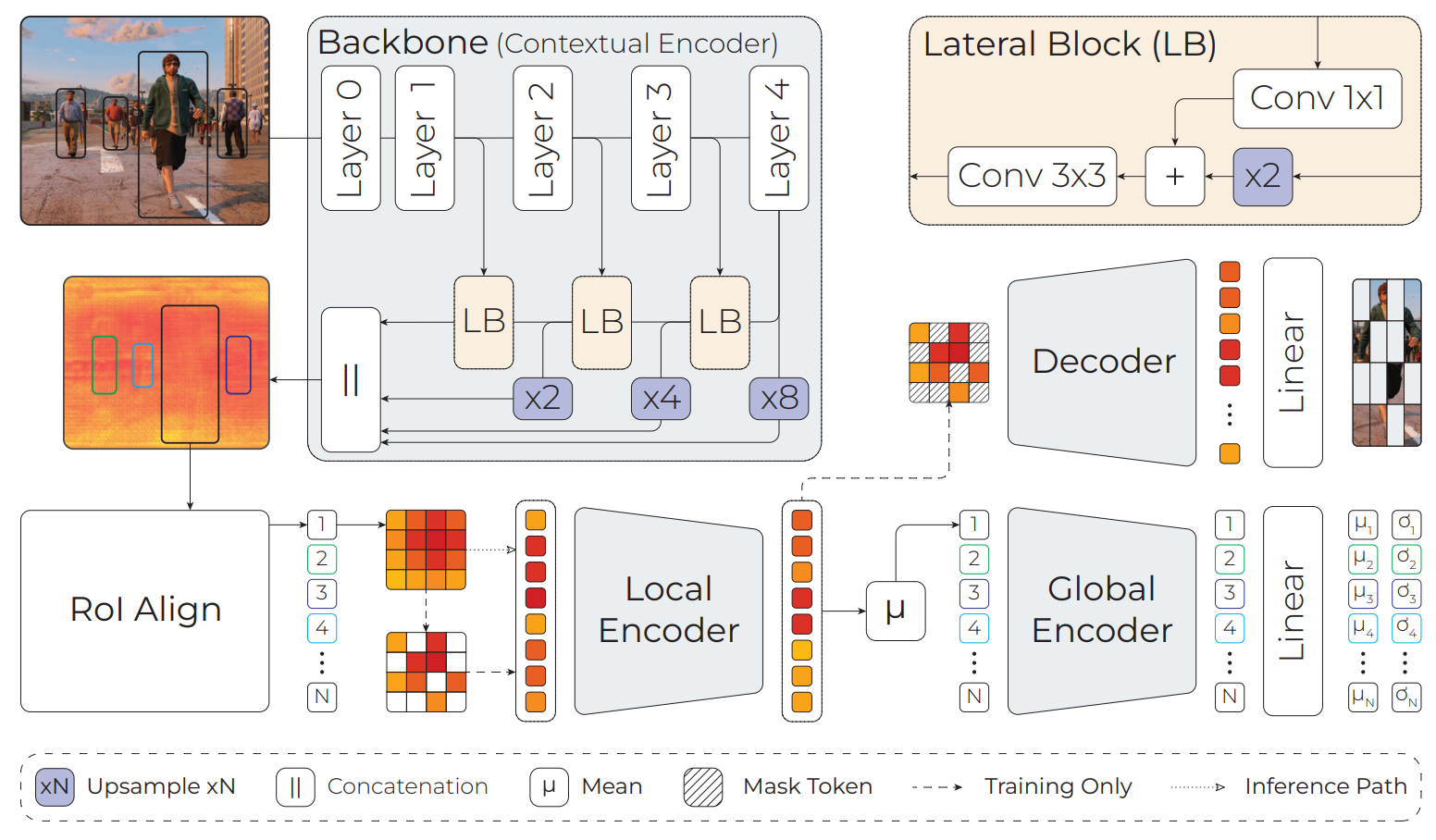
The existing paradigms in distance estimation often grapple with the intricacies of bounding box proportions and global semantic information. DistFormer addresses these limitations by incorporating three key components that work in tandem: a robust context encoder for fine-grained per-object representations, a masked encoder-decoder module leveraging self-supervision for effective feature learning, and a global refinement module that aggregates object representations to compute a joint, spatially-consistent estimation. The synergy of these components sets DistFormer apart and promises advancements in addressing challenges posed by long-range objects, occlusions, and unconventional visual patterns.
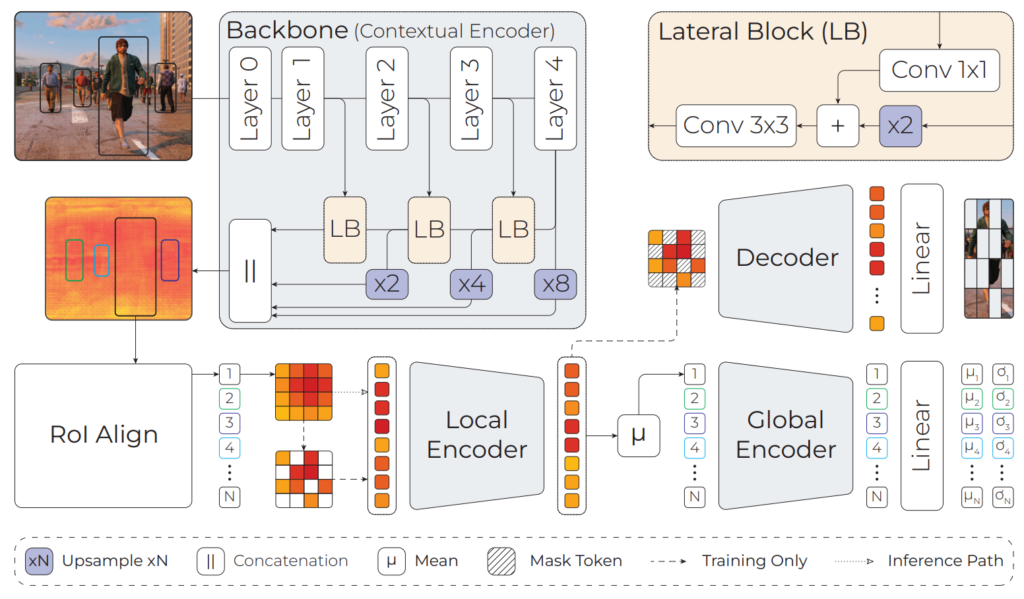
Extensive experiments were conducted on well-established benchmarks to assess the efficacy of DistFormer, including the KITTI dataset and the large-scale NuScenes and MOTSynth datasets. These datasets encompass various indoor and outdoor environments, varying weather conditions, appearances, and camera viewpoints. Our comprehensive analysis demonstrates that DistFormer outperforms existing methods in per-object distance estimation. Furthermore, we delve into its generalization capabilities, showcasing its regularization benefits in zero-shot synth-to-real transfer scenarios.
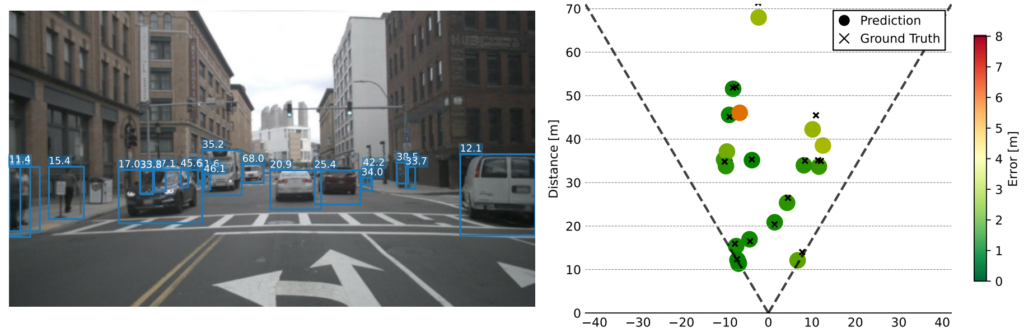
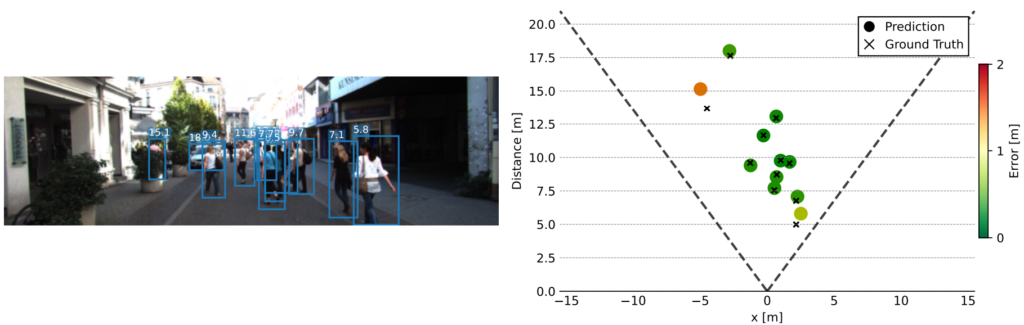
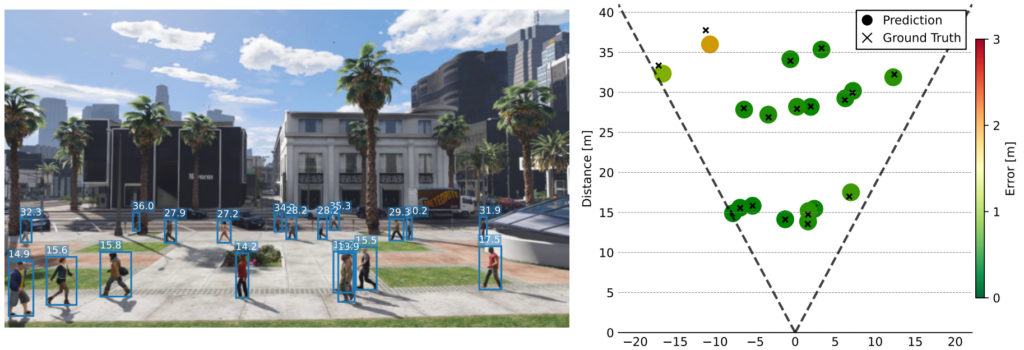
Qualitatives